
2. Narzędzia poziomu wejściowego PL
Narzędzia poziomu wejściowego
 CRM
CRM
Śledź zachowania klientów w całym cyklu sprzedaży, aby zrozumieć bieżące potrzeby i przewidzieć przyszłe potrzeby.
 Analityka internetowa i społecznościowa
Analityka internetowa i społecznościowa
Analizuj ruch w witrynie i mediach społecznościowych oraz zachowania użytkowników, aby ocenić skuteczność Twojej strategii cyfrowej i uzyskać wgląd w rynek.
 VOIP oparty o sieć
VOIP oparty o sieć
Monitoruj źródło i miejsce docelowe połączenia, a także wydajność agenta telefonicznego, aby ocenić kompleksową ofertę produktów i usług.
Wykorzystaj w pełni CRM
ZMAKSYMALIZUJ PRZECHWYTYWANIE DANYCH
Spraw, aby oprogramowanie CRM było łatwe w użyciu. Dowiedz się, czego tak naprawdę chce każdy dział od CRM i dostosuj go.
ZAPEWNIJ WYSOKĄ JAKOŚĆ DANYCH
Zintegruj jak najwięcej źródeł danych. Zidentyfikuj inne systemy obsługi klienta, które można analizować, zwłaszcza media społecznościowe.
Bądź na bieżąco. Wdroż spójny proces aktualizacji danych klientów i zarządzania nimi
ANALIZUJ DANE
Zdefiniuj pytania, na które chcesz uzyskać odpowiedź. Następnie poruszaj się wstecz, aby określić właściwe analizy.
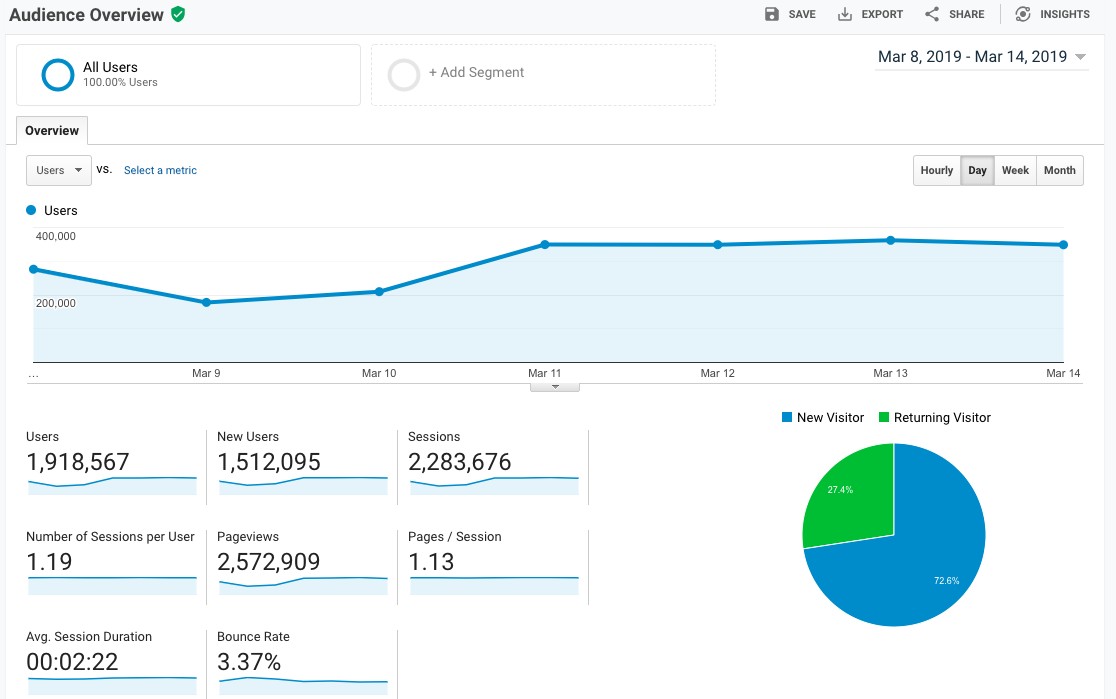
Analityka internetowa i społecznościowa
Pozwala nam na uzyskanie bogatego wglądu do danych
Analiza VOIP
Wykorzystaj analizę śledzenia połączeń, aby:
- Zarządzać przepływem połączeń
- Uzyskać informacje o kliencie
- Określić możliwości korekty i/lub potrzeby szkolenia umiejętności
- Rozpoznawać najlepszych pracowników
Użyj analizy mowy, aby uzyskać jakościowy wgląd w zadowolenie klienta.
.
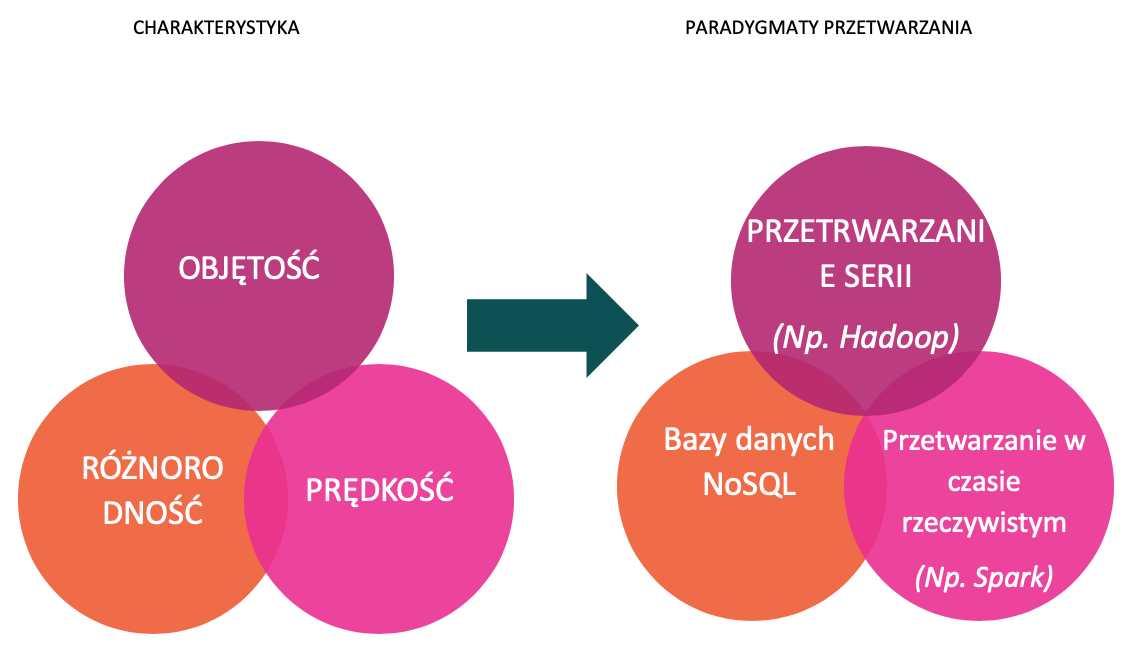
Narzędzia do obsługi dużych zestawów danych
Skalowalna sieć serwerów
Umożliwiają opracowanie operacji na małą skalę, którą można następnie rozszerzyć.
Np. usługi oparte na chmurze
Ramy dla zarządzania danymi
Udostępniają strukturę do łatwego magazynowania i zarządzania różnynu rodzajami przepływów i formatów danych.
Np. pprogramowanie oparte na Hadoop.
Oprogramowanie analityczne
Oprogramowanie o dużych możliwościach wizualizacji danych może pomóc w szybszym przekazywaniu istotnych danych.
Np. Tableau, SAS, SPSS itp.
 HADOOP
HADOOP
Co to jest?
Technologia oprogramowania przygotowana do magazynowania i przetwarzania dużych objętości danych dystrybuowanych między klastrem serwerów i magazynów.
Co zawiera?
- Hadoop Common: Powszechne narzędzia wspierające inne moduły Hadoop
- Hadoop Distributed File System (HDFS): Rozproszony system plików, który przechowuje dane na maszynach towarowych, zapewniając bardzo wysoką łączną przepustowość w całym klastrze,
- Hadoop YARN: platforma zarządzania zasobami odpowiedzialna za zarządzanie zasobami obliczeniowymi w klastrach i wykorzystywanie ich do planowania aplikacji użytkowników,
- Hadoop MapReduce: model programowania do przetwarzania danych na dużą skalę
Jak korzystają z tego firmy?
Hadoop nadaje się do prawie każdego rodzaju obliczeń, które są bardzo iteracyjne; do skanowania terabajtów lub petabajtów danych w jednej operacji. Korzysta z przetwarzania równoległego i jest zorientowany wsadowo lub interaktywnie. Organizacje zwykle używają Hadoop do generowania złożonych modeli analitycznych lub aplikacji do przechowywania dużych ilości danych, takich jak:
- Modelowanie ryzyka,
- Analizy retrospektywne i predykcyjne,
- Uczenie maszynowe i dopasowywanie wzorców,
- Segmentacja klientów
 Spark
Spark
Co to jest?
Uniwersalny silnik przetwarzania rozproszonych danych. Jest podobny do Map Reduce
i innych warstw przetwarzania danych zbudowanych na HDFS w Hadoop.
Jakie zalety ma w porównaniu z Hadoop?
Hadoop opiera się na przetwarzaniu wsadowym, w którym przetwarzane są bloki danych, które były już przechowywane przez pewien czas. Spark był w stanie przetwarzać dane w czasie rzeczywistym i był około 100 razy szybszy niż Hadoop MapReduce w przetwarzaniu wsadowym dużych zestawów danych.
Jak korzystają z tego firmy?
Przetwarzanie strumieniowe: przetwarzanie i działanie na podstawie danych w momencie ich otrzymania. Strumienie danych związane na przykład z transakcjami finansowymi mogą być przetwarzane w czasie rzeczywistym w celu identyfikacji – i odrzucenia – potencjalnie nieuczciwych transakcji.
Uczenie maszynowe: zdolność do przechowywania danych w pamięci i szybkiego uruchamiania powtarzających się zapytań sprawia, że Spark jest dobrym wyborem do ćwiczenia algorytmów uczenia maszynowego do identyfikowania i reagowania na wyzwalacze w ramach znanych już zestawów danych przed zastosowaniem tych samych rozwiązań do nowych i nieznanych danych.
Interaktywna analityka: zamiast uruchamiać wstępnie zdefiniowane zapytania w celu tworzenia statycznych wykresów sprzedaży lub wydajności linii produkcyjnej, analitycy eksplorują swoje dane, zadając pytanie, przeglądając wynik, a następnie nieznacznie zmieniając początkowe pytanie lub głębiej analizując wyniki.
 NoSQL
NoSQL
Co to jest?
Tradycyjnie branże oprogramowania używają relacyjnych baz danych do trwałego przechowywania danych i zarządzania nimi. Jednak duże ilości zestawów danych wprowadziły nowe wyzwania w zakresie przechowywania, zarządzania, analizy i archiwizacji danych. Ponadto dane stają się coraz bardziej „częściowo” ustrukturyzowane. Aby rozwiązać te problemy, pojawiła się klasa nowych produktów bazodanowych składających się z magazynów danych opartych na kolumnach, baz danych pary klucz / wartość oraz baz danych dokumentów. „Nie tylko” SQL lub NOSQL odnosi się do wszystkich baz danych i magazynów danych, które nie są oparte na zasadach Systemu Zarządzania Relacyjną Bazą Danych (Relational Database Management Systems – RDBMS). Nie reprezentuje pojedynczego produktu, grupy produktów i różnych powiązanych koncepcji danych do przechowywania i zarządzania.
Jakie zalety ma w porównaniu z RDBMS?
Dane są przechowywane w wielu różnych bazach danych, nie wymagających tylko wierszy i kolumn, z różnymi modelami przechowywania danych.
RDBMS działa według ustalonego schematu: kolumny są definiowane i blokowane przed wprowadzeniem danych. NoSQL oferuje dynamiczne schematy; możesz dodawać kolumny w dowolnym momencie.
Skalowanie RDBMS na wielu serwerach jest trudnym i czasochłonnym procesem. NoSQL obsługuje skalowanie horyzontalne na wielu serwerach.
 R
R
Co to jest?
R jest językiem programowania statystycznego i środowiskiem wolnego oprogramowania do obliczeń statystycznych i grafiki obsługiwanym przez R Foundation for Statistics Computing. Język R jest szeroko stosowany wśród statystyków i eksploratorów danych do opracowywania oprogramowania statystycznego i analizy danych.
Co obejmuje?
R jest zintegrowanym pakietem oprogramowania do manipulowania danymi, obliczeń i wyświetlania graficznego. Obejmuje:
- centrum przetwarzania i przechowywania danych,
- duży, spójny, zintegrowany zbiór pośrednich narzędzi do analizy danych,
- graficzne funkcje analizy i wyświetlania danych na ekranie lub na papierze, oraz
- dobrze rozwinięty, prosty i skuteczny język programowania, który obejmuje warunki, pętle, zdefiniowane przez użytkownika funkcje rekurencyjne oraz funkcje wejścia i wyjścia.
Jak korzystają z tego firmy?
R jest odpowiedni dla naukowców, inżynierów i profesjonalistów biznesowych, ponieważ zawiera pakiety obejmujące szeroki zakres tematów, takich jak ekonometria, finanse, szeregi czasowe, a także narzędzia do wizualizacji, raportowania i interaktywności.
W szczególności R może tworzyć raporty biznesowe i aplikacje sieciowe oparte na uczeniu maszynowym.